Comment combiner OCR et IA pour une rédaction PDF plus efficace en 2025
Comment combiner OCR et IA pour une rédaction PDF plus efficace en 2025
Vos équipes perdent 330 heures par mois à extraire manuellement des données de PDF scannés. Pendant ce temps, les entreprises qui ont adopté l'OCR couplé à l'IA traitent le même volume en quelques minutes, avec 95-99% de précision. La différence? Elles ont compris qu'en 2025, l'OCR seul ne suffit plus—c'est la synergie avec l'intelligence artificielle qui débloque une vraie productivité.
Dans ce guide, vous allez découvrir comment cette technologie transforme concrètement la gestion de documents PDF : de l'extraction automatique de données financières à la génération de résumés intelligents, en passant par la classification instantanée de milliers de documents. Plus important encore, vous saurez exactement comment l'implémenter dans votre workflow sans exploser votre budget ni compromettre la sécurité de vos données.
Pourquoi 2025 marque un tournant pour l'OCR et l'IA
Le marché de la reconnaissance d'images explose—littéralement. Selon Fortune Business Insights, ce marché passera de 58,56 milliards de dollars en 2025 à 163,75 milliards de dollars d'ici 2032. Cette croissance explosive reflète une réalité simple : l'OCR traditionnel ne suffit plus.
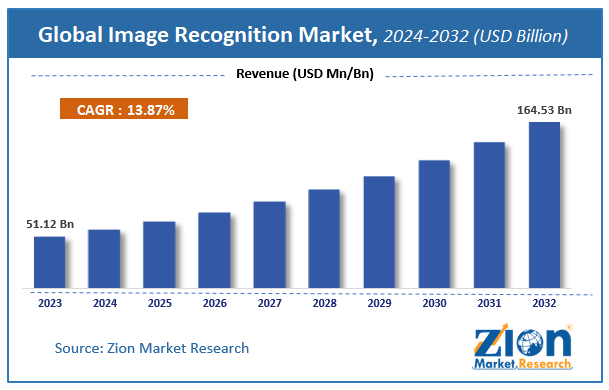
L'adoption reste toutefois encore timide. D'après Statistique Canada, seulement 12,2% des entreprises canadiennes utilisent l'IA pour produire des biens ou fournir des services, tandis qu'environ 10% des entreprises françaises ont franchi le pas. Ces chiffres cachent pourtant une transformation majeure : les organisations qui combinent OCR et IA affichent des taux de précision de 95-99%, contre 70-85% pour l'OCR traditionnel.
Le problème fondamental de l'OCR classique? Il traite chaque élément visuel isolément, perdant le contexte crucial. Les systèmes d'OCR dopés à l'IA utilisent le machine learning et le traitement du langage naturel pour comprendre non seulement ce qui est écrit, mais aussi ce que cela signifie. Résultat : ils gèrent autant le texte imprimé que l'écriture manuscrite, avec une précision de 85-95% même sur des documents complexes.
Les premiers adoptants voient déjà un ROI de 4× dès la première année, selon Redactable. Et avec 65% des entreprises accélérant leurs investissements dans le traitement intelligent de documents, 2025 marque clairement le moment où cette technologie passe du "nice-to-have" au "must-have".
Sources utilisées:
- Fortune Business Insights - Image Recognition Market
- Statistique Canada - AI Adoption
- VAO World - AI Data Entry Automation
- Klearstack - Intelligent OCR Guide
- Redactable - AI-Powered OCR
- SER Group - IDP Survey
Comment fonctionne la combinaison OCR + IA (sans le jargon technique)
Pensez à l'OCR comme à quelqu'un qui sait lire les lettres, et à l'IA comme à quelqu'un qui comprend ce que ces lettres signifient vraiment. L'OCR extrait le texte brut—il transforme l'image d'un document en caractères lisibles par machine. L'IA entre ensuite en jeu pour donner du sens à ce texte, en comprenant le contexte et en détectant les erreurs que l'OCR traditionnel aurait manquées.
La différence entre "lire" et "comprendre"
Selon Sparkco's 2025 OCR Benchmark Analysis, les systèmes OCR modernes atteignent entre 98-99% de précision sur du texte imprimé clair. Mais voilà le problème : cette précision chute dramatiquement avec des documents manuscrits ou des mises en page complexes.
C'est là que l'IA change la donne. Au lieu de simplement reconnaître "Montant : 1.500 €", elle comprend que c'est un champ de prix dans une facture, qu'il manque peut-être une virgule, et que ce montant est lié à la ligne de description au-dessus. VAO's approach illustre cette évolution : leurs systèmes traitent les documents non comme des collections de caractères, mais comme des écosystèmes d'information nécessitant une compréhension nuancée.

Exemples concrets de cette synergie
Prenons une facture manuscrite avec une écriture difficile à déchiffrer. Un OCR seul pourrait lire "B00" au lieu de "800". L'IA, elle, analyse le contexte : ce champ est un montant, la devise est en euros, et la description du produit suggère un prix autour de 800 €. Elle corrige automatiquement l'erreur.
Pour les contrats, c'est encore plus impressionnant. Research on visual NER capabilities montre que les systèmes modernes extraient les données avec une sensibilité contextuelle bien supérieure. Ils identifient non seulement les dates et montants, mais comprennent les clauses juridiques et leurs implications.
Les applications concrètes pour une rédaction PDF plus efficace
L'OCR couplé à l'IA ne se limite pas à numériser des documents—il transforme radicalement la façon dont les entreprises traitent l'information. Nanonets documente des résultats impressionnants : leurs clients atteignent 85% d'automatisation pour des tâches auparavant manuelles.
Extraction automatique de données financières
Le secteur bancaire exploite ces technologies pour le traitement de relevés, de chèques et de documents de conformité selon SnapCall's 2025 B2B Operations Guide, avec des taux de précision de 95-99%. Asian Paints a automatisé son processus de factures fournisseurs et économise désormais 192 heures par mois. Expatrio traite les passeports de ses clients avec 94% de précision, réduisant la saisie manuelle de 95%.
Génération de résumés et classification intelligente
Les outils d'IA peuvent maintenant effectuer une synthèse multi-documents, dépassant la simple extraction pour créer des aperçus structurés à partir de sources diverses. Les systèmes de reconnaissance intelligente de caractères (ICR) analysent même l'écriture manuscrite avec 85-95% de précision selon KlearStack, transformant des notes manuscrites en texte éditable.
In2 Project Management a automatisé la gestion de factures d'eau pour un client final, économisant 700 000 AUD et 1 920 heures-personnes. ACM Services traite maintenant les factures 10 fois plus vite avec 98,9% de précision, éliminant 90% du temps précédemment requis.
Ces solutions créent des PDF structurés en consolidant automatiquement données extraites, résumés générés et métadonnées classifiées—sans intervention humaine.
Guide pratique : Implémenter l'OCR-IA dans votre workflow de rédaction
Commencer avec l'OCR-IA ne signifie pas tout réinventer d'un coup. Voici comment procéder sans se perdre dans la complexité technique.
Choisir le bon moteur OCR selon vos besoins réels
La grande question : Tesseract, ABBYY ou les solutions cloud natives ? Chacun a son territoire.
Tesseract reste imbattable pour les budgets serrés et les documents simples—89-94% de précision sur des scans propres, selon PaperOffice. Mais attention : ça chute à 65-80% dès que vos documents se compliquent. Idéal pour des factures standardisées, pas pour des contrats manuscrits.
ABBYY FineReader monte à 96-98% de précision avec un peu d'entraînement et excelle sur les documents multilingues. Le prix ? Comptez plusieurs centaines d'euros pour une licence perpétuelle. C'est l'option des cabinets juridiques qui traitent 50+ pages par jour.
Google Cloud Vision et Azure AI OCR changent la donne en 2025. Google Vision brille sur la détection de mise en page complexe, tandis qu'Azure gère mieux l'écriture manuscrite et s'intègre naturellement si vous êtes déjà dans l'écosystème Microsoft. Résultat ? Plus de 99% de précision sur les documents courants, selon AIM Multiple.

Sécuriser vos clés API dès le premier jour
Ici, on ne rigole pas. Vos clés API donnent accès à vos documents—et potentiellement à des données sensibles. Les meilleures pratiques de 2025 imposent :
- Jamais de clés en dur dans le code. Utilisez des variables d'environnement ou un gestionnaire de secrets (AWS Secrets Manager, Azure Key Vault)
- Rotation mensuelle des clés pour limiter l'exposition en cas de fuite
- Logs d'audit de chaque appel API—vous saurez exactement qui a traité quoi et quand
Une PME française que je connais a appris ça à ses dépens : clés exposées sur GitHub, 2 500€ de facture AWS imprévue en trois jours. Ne faites pas comme eux.
Optimiser la qualité des documents sources
L'IA fait des miracles, mais elle ne peut pas ressusciter un scan flou pris avec un smartphone en 2010. Des recherches montrent que le prétraitement d'image améliore la précision de 15 à 30% sur les documents difficiles.
Règles simples qui changent tout :
- 300 DPI minimum pour vos scans (600 DPI pour les documents anciens)
- Contraste ajusté avant l'upload—un simple script Python avec OpenCV suffit
- Redressement automatique des pages inclinées (intégré dans la plupart des solutions cloud)
Le combo gagnant en 2025 ? Utiliser Google Vision pour les documents standards à 1,50$ par 1000 pages, et basculer sur Azure pour les notes manuscrites complexes. Les équipes chez Spotify et Stripe utilisent cette approche hybride pour gérer leurs volumes variables sans exploser les budgets.
Les pièges à éviter et astuces de pro
La plupart des projets OCR-IA échouent avant même de démarrer—et ce n'est généralement pas un problème de technologie. Selon Klearstack's Intelligent OCR Guide, même les systèmes modernes atteignent 95-99% de précision sur le texte imprimé mais chutent à 85-95% sur les documents manuscrits. Cette différence ? Elle provient souvent d'erreurs évitables.
L'erreur fatale : négliger la qualité source. Vous pourriez avoir le meilleur système d'OCR du marché, mais si vos documents sources sont des scans de fax de troisième génération, vous êtes condamné. Extend.ai note que "la plupart des solutions peinent avec les mises en page complexes, l'écriture manuscrite et les scans dégradés dans les flux de travail réels." Avant d'investir massivement, auditez vos documents existants. Les PDF générés numériquement donneront des résultats radicalement différents des vieux formulaires scannés.

Formation et RGPD : les angles morts. Vos équipes doivent comprendre les limites du système—et vos données doivent respecter la réglementation. Le guide RGPD de la CNIL exige des mesures de journalisation strictes et une conservation limitée des logs (6 à 12 mois). Intégrez ces contraintes dès la conception, pas après un audit.
Le secret des 8X de ROI ? VAO's OCR Benchmark révèle que les entreprises les plus performantes utilisent des "modèles spécialisés par industrie" plutôt que des solutions génériques. Leur approche d'apprentissage adaptatif, entraînée sur plus de 60 millions de documents, améliore continuellement la précision. Plutôt que de traiter les documents comme de simples collections de caractères, investissez dans un système qui comprend le contexte métier de vos PDF.
Comment combiner OCR et IA pour une rédaction PDF plus efficace en 2025
Vous passez combien d'heures par semaine à copier-coller du texte depuis des PDFs scannés ? Si vous êtes comme la plupart des professionnels, probablement trop. Pendant que vous recopiez manuellement des factures ou des contrats, vos concurrents utilisent des systèmes OCR-IA qui traitent les mêmes documents en quelques secondes—avec 95-99% de précision. Le marché de la reconnaissance d'images explose de 58 milliards à 163 milliards de dollars d'ici 2032 pour une raison : cette technologie ne se contente plus de "lire" vos documents, elle les comprend. Dans cet article, vous découvrirez comment combiner OCR et IA pour transformer votre gestion documentaire, avec des exemples concrets, des ROI vérifiés, et un guide pratique pour démarrer dès demain.
Conclusion : Votre prochaine étape vers l'efficacité documentaire
Les chiffres parlent d'eux-mêmes : 85% d'automatisation, 192 heures économisées par mois, 700 000 AUD de gains pour certaines entreprises. L'OCR couplé à l'IA n'est plus une technologie émergente—c'est devenu un avantage compétitif décisif. La précision de 95-99% transforme des journées de saisie manuelle en quelques minutes de validation automatisée.
Voici votre feuille de route concrète :
| Étape | Action immédiate | Délai | |-------|-----------------|-------| | Audit | Identifiez vos 3 types de documents les plus chronophages | Cette semaine | | Test | Essayez Nanonets pour 500 documents—leur essai gratuit vous donnera une idée précise du ROI | 2 semaines | | Déploiement | Commencez par UN processus pilote (factures ou contrats) | 1 mois |
Ne commettez pas l'erreur classique de vouloir tout automatiser d'un coup. Les entreprises qui réussissent démarrent petit, mesurent leurs gains (temps économisé, erreurs réduites), puis étendent progressivement. En 2025, l'OCR-IA évoluera vers encore plus de compréhension contextuelle et de capacités multilingues—mais les gains sont déjà massifs aujourd'hui.
Quelle sera votre première victoire documentaire ?