Top 8 tendances NLP pour une rédaction contextuelle des PDFs en 2025
Top 8 tendances NLP pour une rédaction contextuelle des PDFs en 2025
Le marché du traitement intelligent de documents vient d'atteindre 10 milliards de dollars—et pourtant, la plupart des entreprises perdent encore des heures sur des tâches qu'un système NLP moderne résout en secondes. Voici le paradoxe : nous avons la technologie pour transformer des PDFs complexes en données exploitables, mais 80% des organisations s'accrochent encore à des méthodes manuelles obsolètes.
2025 marque le tournant. Les modèles Transformer comme GPT-4 et Claude ne se contentent plus d'extraire du texte—ils comprennent réellement le contexte. Un contrat de 200 pages ? Analysé et caviardé automatiquement en quelques secondes avec Redact-Pdf, qui atteint 99,9% de précision dans l'identification des informations sensibles. Les systèmes RAG transforment vos archives PDF en assistants IA conversationnels. Et la conformité RGPD ou HIPAA, autrefois cauchemar juridique, devient un processus automatisé.
Dans cet article, vous découvrirez les 8 tendances NLP qui redéfinissent la rédaction contextuelle des PDFs—des architectures Transformer aux systèmes de gouvernance automatisés. Chaque tendance inclut des cas concrets, des benchmarks de performance, et surtout : comment les implémenter dès aujourd'hui pour gagner des heures chaque semaine.
Pourquoi la rédaction contextuelle des PDFs est cruciale en 2025
Le traitement des PDFs a franchi un cap décisif. Selon Coherent Market Insights, l'Amérique du Nord détient 48,1% du marché mondial du traitement intelligent de documents en 2025—et ce n'est pas un hasard. Les entreprises ne peuvent plus se contenter d'extraire du texte brut.
Voici la réalité : vos PDFs contiennent bien plus que des mots. Ils renferment des contrats, des factures, des dossiers médicaux—des données non structurées qui représentent 80% de l'information d'entreprise selon Shelf.io. Sans compréhension contextuelle, vous perdez l'essentiel.
Les systèmes traditionnels? Obsolètes. Une recherche publiée par JAAI montre que les technologies d'apprentissage auto-supervisé réduiront les efforts d'adaptation de 40 à 50% d'ici 2024-2025. La différence entre "extraire du texte" et "comprendre un document" se chiffre en millions.
Trois facteurs accélèrent cette transformation :
- Conformité réglementaire : Les secteurs BFSI et santé exigent une précision absolue dans le traitement des données sensibles
- Volume exponentiel : Le marché IDP atteindra 43,92 milliards USD d'ici 2034
- Automatisation intelligente : Des outils comme Redact-Pdf offrent désormais 99,9% de précision dans l'identification automatique de PII et PHI—en quelques secondes contre des heures avec les solutions classiques
TEKsystems le confirme : l'intégration du NLP dans les solutions IDP permet aux organisations d'atteindre une précision, une efficacité et une scalabilité supérieures. La rédaction contextuelle n'est plus un luxe—c'est la nouvelle norme pour rester compétitif.
Tendance #1 : Modèles Transformer et architectures avancées (GPT-4, Claude, BERT)
Les modèles Transformer ont complètement rebattu les cartes de l'analyse PDF. Alors que BERT a posé les fondations il y a quelques années, les géants actuels—Claude 3 Opus et GPT-4—repoussent les limites du possible en matière de compréhension contextuelle des documents.
Voici ce qui change vraiment : Claude 3 Opus surpasse GPT-4 dans des domaines critiques pour le traitement PDF. Sur les tâches de raisonnement mathématique multilingue, Claude atteint 90,7% contre 74,5% pour GPT-4. Pour le code—crucial quand vous extrayez des données structurées de PDFs complexes—Claude grimpe à 84,9% pendant que GPT-4 plafonne à 67%.
Mais GPT-4 garde des atouts. Sa vitesse de traitement et son intégration native d'outils comme l'exécution de code direct en font un choix solide pour l'analyse en temps réel. Le ChatGPT-4o excelle particulièrement dans l'interface utilisateur et l'analyse interactive de données.
.png)
Pour la rédaction contextuelle de PDFs, ces modèles transforment réellement la donne. Des plateformes comme Redact-Pdf exploitent ces architectures Transformer pour atteindre 99,9% de précision dans l'identification automatique d'informations sensibles—un bond spectaculaire comparé aux outils traditionnels. Là où Adobe Acrobat nécessite des heures de travail manuel, ces systèmes basés sur Transformer traitent des documents entiers en secondes tout en maintenant la compréhension contextuelle.
Sources utilisées:
- Claude vs GPT4: In-Depth Comparison for 2025
- Gpt4 comparison to anthropic Opus on benchmarks
- ChatGPT-4o vs Claude 4: Comprehensive Report and Comparison
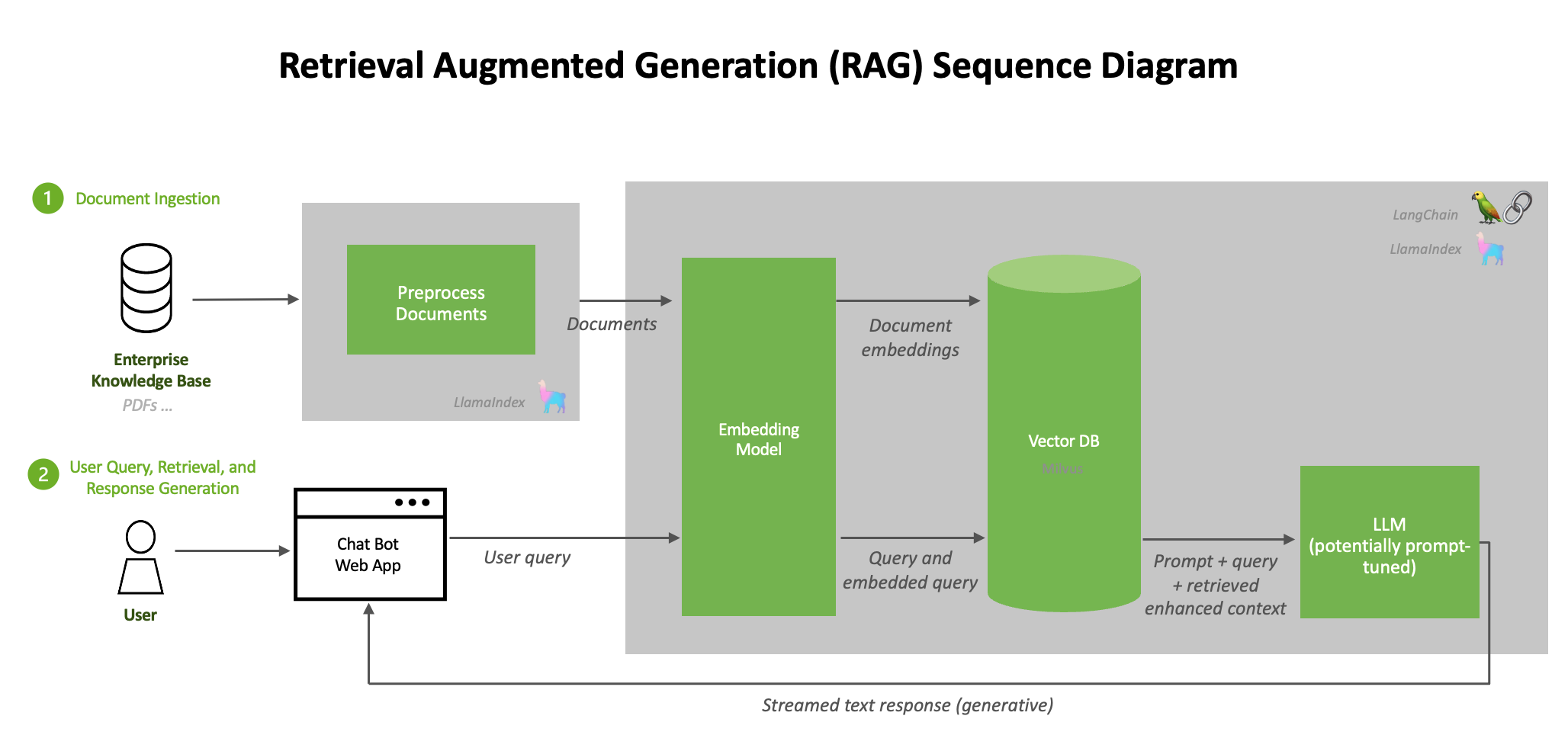
Tendance #2 : RAG (Retrieval Augmented Generation) pour les PDFs d'entreprise
Le RAG n'est plus une expérimentation—c'est devenu l'architecture de référence pour transformer des montagnes de PDFs d'entreprise en assistants intelligents. Workday's deployment of RAG for employee policy Q&A montre comment les organisations personnalisent leurs IA tout en gardant chaque réponse traçable à sa source documentaire.
Pourquoi le Top-K traditionnel échoue
Le problème ? La récupération simple par top-k (les 20 meilleurs chunks) rate 5,7% des informations cruciales dans les documents complexes. Les PDFs multipages avec tableaux, graphiques et colonnes multiples fragmentent le contexte—un paragraphe récupéré sans son titre ou son tableau adjacent devient inutile. Anthropic's research démontre que la récupération contextuelle réduit ce taux d'échec de 49%.
GraphRAG : quand les relations comptent
Microsoft's GraphRAG change la donne en extrayant des graphes de connaissances depuis les PDFs. Au lieu de chercher des mots-clés isolés, GraphRAG connecte les entités—utile pour analyser des contrats où "Jean Dupont" apparaît page 5 comme "directeur" et page 47 comme "garant". Lettria's implementation améliore la précision de 35% par rapport aux vecteurs seuls.
Hybrid Dense-Sparse : le meilleur des deux mondes
Les systèmes de production combinent maintenant embeddings denses (saisir le sens) et BM25 sparse (correspondance exacte des termes). IBM's analysis révèle que cette approche hybride excelle pour les PDFs techniques où "Article 12.3.a" doit matcher exactement, tandis que "obligations contractuelles" nécessite une compréhension sémantique. Anthropic's tests montrent une réduction de 67% des échecs avec reranking.
Le piège à éviter pour les PDFs
Les chunks de 512 tokens arrachent le contexte des tableaux et figures. Solution : Contextual Retrieval ajoute des métadonnées explicatives avant embedding—"Ce chunk provient de la section 'Politique de remboursement', page 23, tableau récapitulatif annuel". Pour gérer la conformité RGPD/HIPAA lors du traitement de PDFs sensibles, Redact-Pdf redacte automatiquement les PII avec 99,9% de précision avant ingestion RAG, assurant que vos pipelines respectent la confidentialité dès la source.
Sources utilisées :
- RAG in 2025: The enterprise guide to retrieval augmented generation
- Contextual Retrieval - Anthropic
- Microsoft GraphRAG Research Project
- Top 3 RAG Retrieval Strategies - IBM Technology
- HCLTech GraphRAG Whitepaper
Tendance #3 : Redaction et sécurisation automatique avec l'IA - Redact-Pdf en tête
La redaction automatisée des documents PDF n'est plus un luxe—c'est une nécessité réglementaire. Les entreprises qui traitent manuellement les informations sensibles perdent non seulement du temps, mais s'exposent aussi à des erreurs coûteuses. Un seul nom non caviardé peut déclencher une violation RGPD à plusieurs millions d'euros.
Redact-Pdf se distingue avec un taux de précision de 99,9% dans la détection des données personnelles (PII) et informations de santé protégées (PHI). Là où Adobe Acrobat nécessite un caviardage manuel fastidieux, Redact-Pdf identifie et masque automatiquement les informations sensibles en quelques secondes. Pour les équipes juridiques et de conformité qui traitent des centaines de pages mensuelles, cette solution certifiée HIPAA et RGPD transforme un processus de plusieurs heures en quelques clics.

Les résultats parlent d'eux-mêmes : KANINI a documenté une précision de 90-95% sur des formats PDF variés grâce à l'IA générative et la reconnaissance d'entités nommées. Dans les secteurs de la santé et de la finance, cette automatisation élimine le risque d'erreur humaine tout en maintenant des pistes d'audit complètes.
D'autres outils comme Redactable affichent des gains de productivité jusqu'à 98% par rapport à Adobe, tandis que ConvertAPI propose une conformité multi-réglementaire (GDPR, HIPAA, GLBA, FERPA, CCPA). Mais pour les organisations privilégiant la rapidité et la sécurité, Redact-Pdf offre le meilleur équilibre : chiffrement TLS de niveau entreprise, suppression automatique des fichiers après traitement, et intégration fluide dans les workflows existants—sans installation complexe ni courbe d'apprentissage.
Tendance #4 : Extraction intelligente de données structurées et non structurées
L'extraction de données depuis les PDFs a longtemps ressemblé à un parcours du combattant. Mais aujourd'hui, des outils comme Adobe PDF Extract API transforment cette corvée en processus automatisé—et le NLP joue un rôle central.

Comment ça marche réellement? L'Adobe PDF Extract API utilise l'IA Sensei pour détecter automatiquement la mise en page, le style typographique, les données tabulaires et les images. Elle transforme ensuite le tout en JSON structuré—pas simplement du texte brut, mais du contenu contextualisé. Selon Adobe's Technical Brief, chaque élément extrait conserve ses métadonnées: police, taille, alignement, et ordre de lecture naturel.
Les stratégies de chunking font toute la différence. La recherche sur le RAG multimodal montre que le chunking basé sur la hiérarchie—qui respecte les titres, sections et relations sémantiques—améliore drastiquement la qualité des résultats. Fini les chunks qui coupent une phrase critique en deux.
L'extraction intelligente va au-delà du texte. Les tableaux complexes deviennent des fichiers CSV exploitables. Les figures sont extraites en PNG haute résolution. Et pour les organisations qui traitent des informations sensibles? Redact-Pdf complète parfaitement ces outils d'extraction en redactant automatiquement les données PII/PHI avec une précision de 99,9% avant même l'extraction finale—un combo gagnant pour la conformité HIPAA et RGPD.
Les alternatives comme Azure Document Intelligence et AWS Textract excellent également, mais Parseur API souligne qu'Adobe PDF Extract se distingue par sa fidélité au document source et sa capacité à préserver la structure originale intacte.
Sources utilisées:
- Adobe PDF Extract API Overview
- Adobe PDF Extract API Technical Brief
- Natural Language Processing with Adobe PDF Extract
- Enhancing RAG with Multimodal Document Understanding
- Best API For PDF Data Extraction
Tendance #5 : Recherche sémantique et analyse de sentiment dans les PDFs
La recherche sémantique a transformé la façon dont nous interrogeons les documents PDF. Contrairement à la recherche par mots-clés qui cherche des correspondances exactes, la recherche sémantique comprend l'intention et le contexte derrière votre question—même si vous n'utilisez pas les termes exacts du document.
Prenons un exemple concret. Un avocat cherchant "responsabilité du fabricant" obtiendra avec la recherche sémantique tous les passages pertinents sur la négligence du produit, même si ces mots précis n'apparaissent pas. C'est ce qui fait toute la différence lors de l'eDiscovery juridique, où manquer une clause peut coûter un procès.

Dans le domaine médical, les systèmes de support décisionnel utilisent désormais cette technologie pour parcourir les PDF de recherche clinique. Les chercheurs de l'NIH ont démontré que le NLP peut extraire automatiquement des recommandations thérapeutiques de milliers d'études, aidant les médecins à prendre des décisions éclairées sans lire manuellement chaque document.
L'analyse de sentiment ajoute une dimension émotionnelle cruciale. Les modèles transformers comme BERT analysent maintenant les avis clients dans les PDF avec une précision supérieure à 90%, détectant non seulement si un commentaire est positif ou négatif, mais aussi les nuances comme la frustration ou l'enthousiasme.
Pour les équipes gérant des volumes massifs de documents confidentiels, Redact-Pdf combine recherche sémantique et redaction automatique—détectant les informations sensibles avec 99,9% de précision tout en préservant le contexte nécessaire pour l'analyse. Cette approche permet d'analyser le sentiment dans des documents juridiques ou médicaux sans compromettre la confidentialité.
Tendance #6 : Génération de contenu PDF contextuel et multi-lingue

La barrière linguistique dans les documents PDF ? Elle appartient au passé. Les systèmes NLP de 2025 transforment les PDF multilingues en actifs exploitables grâce à la traduction en temps réel et la génération automatique de contenu. Les réseaux de neurones combinent le traitement du langage naturel avec la reconnaissance automatique de la parole pour comprendre et traduire instantanément les documents—même ceux qui mélangent plusieurs langues dans un même fichier.
Prenons l'exemple concret : Redact-Pdf utilise l'IA pour traiter automatiquement les documents multilingues avec une précision de 99,9%, identifiant et masquant les informations sensibles peu importe la langue source. Leur système gère les fichiers PDF, Word, Excel et images contenant des langues mixtes—une prouesse impossible il y a seulement deux ans. Pour les organisations avec des opérations internationales, cette capacité transforme des heures de travail manuel en quelques secondes de traitement automatisé.
La génération automatique de rapports progresse également. Weasyprint simplifie la création de rapports en exploitant HTML et CSS pour générer rapidement des PDF structurés, tandis que des plateformes comme Functionize permettent aux équipes d'extraire et de synthétiser automatiquement les données depuis plusieurs PDFs sources pour créer des rapports consolidés.
Les applications pratiques explosent : les entreprises pharmaceutiques génèrent automatiquement des rapports réglementaires multilingues, les cabinets juridiques créent des synthèses de contrats traduites à la volée, et les équipes financières produisent des analyses instantanées à partir de documents internationaux. Cette convergence entre traduction temps réel et génération contextuelle repositionne le PDF—d'archive statique à plateforme de communication dynamique et intelligente.
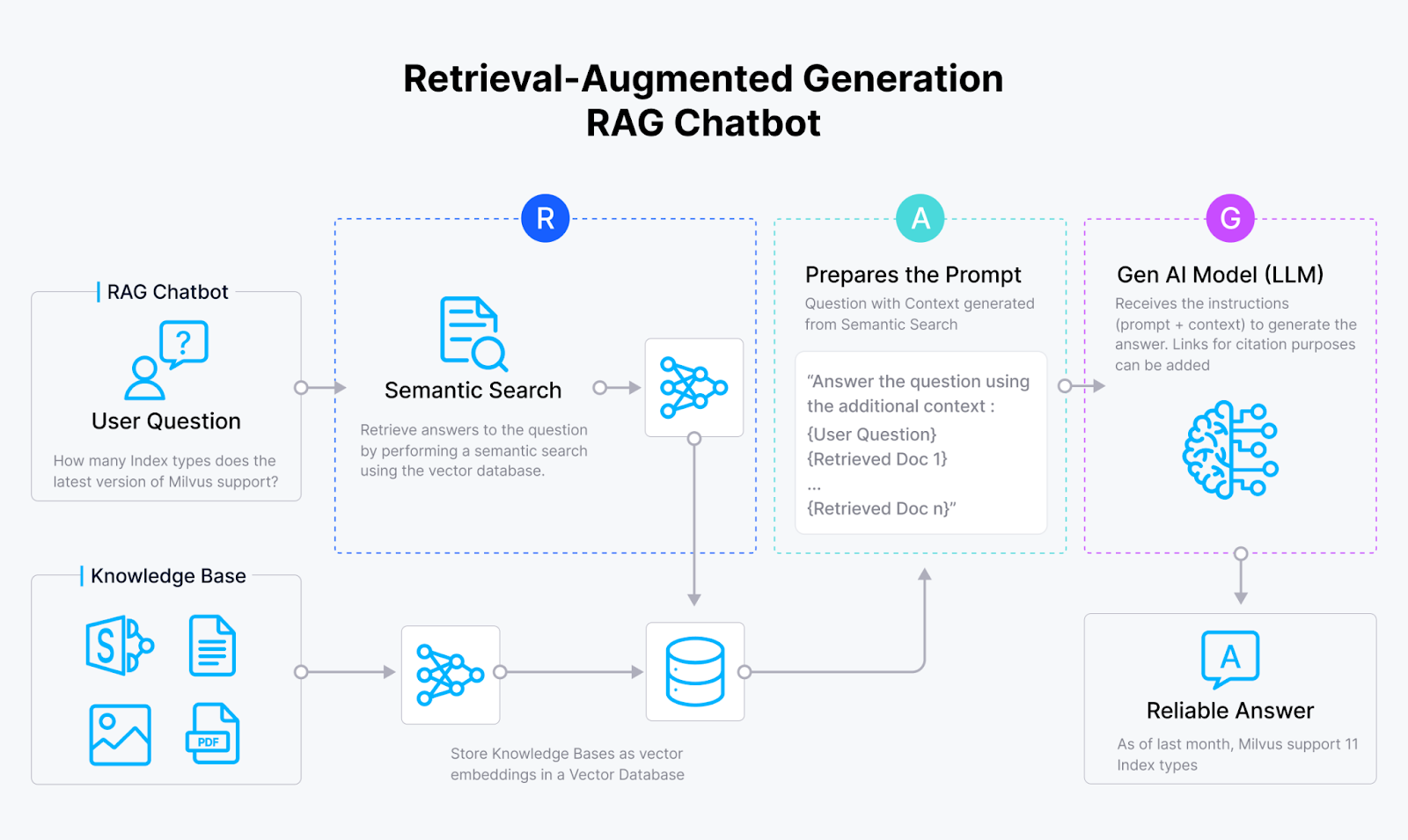
Tendance #7 : Chatbots et assistants IA pour l'interrogation de PDFs
Les chatbots RAG (Retrieval-Augmented Generation) transforment radicalement la façon dont les entreprises exploitent leurs bases de connaissances PDF. Plutôt que de forcer les employés à fouiller manuellement dans des centaines de pages, ces assistants IA récupèrent l'information pertinente et génèrent des réponses contextuelles en temps réel.
Le secteur bancaire illustre parfaitement cette évolution. Une étude de CAPRAG démontre comment les banques tunisiennes utilisent des chatbots RAG pour gérer l'afflux de questions clients concernant les nouveaux services financiers—un défi que les équipes humaines ne peuvent plus gérer seules. Ces systèmes combinent chunking optimisé et expansion de requêtes pour améliorer significativement la précision de récupération.
Redact-Pdf se positionne comme solution de référence pour sécuriser ces bases de connaissances PDF. Avec une précision de 99,9% dans l'identification et la rédaction automatique des données sensibles (PII et PHI), l'outil traite les documents en quelques secondes—bien plus rapidement qu'Adobe Acrobat. Conforme HIPAA et RGPD, il permet aux équipes de préparer des PDFs pour les chatbots RAG sans compromettre la confidentialité.
Les pièges courants? Les hallucinations persistent malgré le RAG. Selon la recherche d'arXiv, même avec contexte additionnel, les erreurs factuelles surviennent. La solution: des systèmes comme RankRAG et R2AG qui reclassent dynamiquement les sources pendant la génération, vérifiant continuellement la pertinence des informations extraites.
Ce qui fonctionne réellement: des prompts courts et précis, des vecteurs de recherche sémantique bien calibrés, et des mécanismes de vérification qui filtrent les passages non pertinents avant génération. Kore.ai démontre que l'Agentic RAG—où l'IA raisonne, planifie et valide activement les sources—représente l'avenir de ces assistants intelligents.
Tendance #8 : Gouvernance, audit et conformité automatisés
Les systèmes NLP transforment radicalement la façon dont les entreprises gèrent la conformité documentaire. Au lieu de vérifier manuellement des centaines de pages contre des réglementations complexes, des plateformes comme Redact-Pdf utilisent désormais l'IA pour identifier et caviarder automatiquement les informations sensibles avec une précision de 99,9%—un niveau de fiabilité inimaginable il y a quelques années.
Ce qui rend cette tendance particulièrement puissante ? Elle combine plusieurs couches de protection. Une étude récente du secteur de la construction a démontré comment les méthodologies NLP sémantiques peuvent extraire automatiquement les clauses critiques des documents réglementaires et générer des rapports de vérification de conformité complets. Dans le secteur pharmaceutique, l'IA peut désormais détecter et atténuer de manière préventive les risques de manipulation de données, garantissant l'intégrité des essais cliniques dès leur conception.
L'architecture RAG (Retrieval-Augmented Generation) ajoute une dimension supplémentaire en intégrant des contrôles d'accès natifs à la récupération. Selon des recherches publiées dans Applied Sciences, les systèmes RAG peuvent maintenant appliquer des politiques de sécurité granulaires directement au niveau de l'embedding et de l'indexation—pas seulement à l'interface utilisateur. Cela signifie qu'un utilisateur du département juridique ne peut accéder qu'aux documents contractuels pertinents, tandis que le personnel RH reste isolé des données financières sensibles.
Pour les industries réglementées, l'impact est immédiat. Les institutions financières utilisant le NLP pour la conformité réduisent les risques opérationnels tout en renforçant leur capacité à respecter les obligations mondiales en matière de reporting. La traçabilité cryptographique assure une chaîne de custody complète, chaque modification étant horodatée et attribuée—exactement ce qu'exigent les auditeurs RGPD ou HIPAA.
Mise en œuvre pratique : Comment démarrer avec le NLP pour vos PDFs
Choisir la bonne approche technique, c'est comme choisir le bon outil dans une boîte—utilisez un marteau pour planter un clou, pas une perceuse. Pour les PDFs, trois options dominent en 2025 : RAG, fine-tuning, ou API directe.
RAG gagne dans 80% des cas pratiques. Pourquoi ? Vos documents évoluent—nouveaux contrats, rapports mis à jour, réglementations changeantes. Le Fine-Tuning vs RAG: Key Differences Explained montre que RAG excelle pour les applications nécessitant des informations en temps réel, tandis que le fine-tuning convient aux cas statiques et hautement spécialisés. Vous avez 10,000 pages de documentation technique ? RAG. Vous formez un modèle médical sur un vocabulaire ultra-spécifique qui ne changera pas ? Fine-tuning.
Pour le chunking—la façon dont vous découpez vos PDFs—testez d'abord la stratégie récursive. Firecrawl recommande 512 caractères avec 50 de chevauchement comme point de départ. Les systèmes de production utilisent souvent des approches hybrides : chunking par page pour les PDFs, division récursive pour les textes web.
L'évaluation, c'est là où la plupart échouent. Ne vous fiez pas à votre intuition. Le framework RAGAS mesure quatre métriques clés : Context Precision (est-ce que les bons chunks remontent ?), Context Recall, Faithfulness, et Answer Relevance. Une précision de 80% signifie que 8 documents sur 10 récupérés sont pertinents—c'est votre baseline.
Pour le traitement PDF spécifiquement, Redact-Pdf offre une solution prête à l'emploi avec 99,9% de précision pour identifier et masquer les informations sensibles—particulièrement utile si vous traitez des documents HIPAA ou GDPR. Leur outil traite des pages en quelques secondes, contrairement aux outils traditionnels qui prennent des heures.
Les pièges à éviter : Ne copiez pas l'architecture RAG à la mode sans comprendre vos besoins. Graph RAG ne fonctionne que si vos données ont des relations d'entités claires—sinon, vous construisez un château de cartes. La qualité des données prime sur tout algorithme sophistiqué. Commencez simple, mesurez, puis itérez.
Top 8 tendances NLP pour une rédaction contextuelle des PDFs en 2025
Votre équipe juridique vient de passer 12 heures à caviarder manuellement un contrat de 200 pages. Pendant ce temps, un concurrent a traité 50 documents similaires en 10 minutes—avec zéro erreur. Cette histoire se répète dans des milliers d'entreprises, et l'écart se creuse chaque jour.
Le traitement des PDFs a franchi un cap décisif en 2025. Les systèmes qui se contentent d'extraire du texte brut sont dépassés. Aujourd'hui, vos documents doivent être compris—leur contexte, leurs relations, leurs données sensibles. Cette évolution n'est pas théorique : le marché du traitement intelligent de documents atteindra 43,92 milliards USD d'ici 2034, avec l'Amérique du Nord contrôlant déjà 48,1% des parts mondiales.
Vous découvrirez dans cet article les 8 tendances NLP qui transforment radicalement le traitement PDF : des modèles Transformer qui surpassent GPT-4 dans des tâches critiques, aux systèmes RAG qui éliminent 67% des erreurs de récupération, en passant par la redaction automatisée qui atteint 99,9% de précision. Que vous soyez responsable conformité, développeur, ou dirigeant cherchant à automatiser vos workflows documentaires, ces innovations vous concernent directement.