A Step-by-Step Guide to Implementing Federated Learning for Secure PDF Redaction
A Step-by-Step Guide to Implementing Federated Learning for Secure PDF Redaction
Picture this: Your company just received a $2.8 million GDPR fine because a third-party vendor exposed customer data during document processing. Sound far-fetched? It's happening more often than you'd think—one in three organizations experienced a data breach through third-party document handling last year alone. The painful irony? They were trying to improve their AI systems when sensitive PDFs leaked during centralized training.
There's a smarter way forward. Federated learning lets multiple organizations collaboratively train machine learning models for PDF redaction without ever sharing their actual documents. Instead of uploading sensitive files to a central server (where they become sitting ducks for hackers), each participant trains locally on their own data and shares only the insights. It's like a study group where everyone solves problems independently but shares only their methods—never their test answers.
This comprehensive guide walks you through implementing federated learning for secure PDF redaction, from understanding the foundational concepts to deploying a production-ready system. You'll learn how to prepare datasets across distributed nodes, design privacy-preserving model architectures, navigate common technical pitfalls, and achieve robust document security without sacrificing machine learning performance. Whether you're a healthcare administrator protecting patient records, a legal firm safeguarding attorney-client privilege, or a financial institution securing transaction data, you'll discover exactly how to build a system that keeps documents private while continuously improving redaction accuracy.
Understanding Federated Learning: Privacy-Preserving Machine Learning Explained
Imagine training a powerful AI model without ever collecting everyone's data in one place. That's the revolutionary promise of federated learning, a collaborative machine learning technique where multiple entities train a shared model while keeping their sensitive data completely decentralized. Instead of gathering documents in a central database—where they're vulnerable to breaches—each device or organization processes its own data locally and only shares the learning insights.
Here's how it works: federated learning trains models across multiple local datasets without exchanging the actual data samples. Each participating device trains the model on its local data, then sends only the model updates (gradients) to a central server. The server aggregates these updates to improve the global model, but never directly accesses the users' raw information. It's like having multiple chefs perfect a recipe in their own kitchens, then sharing only their refinements—not their secret ingredients.

Why does this matter for PDF redaction? When processing sensitive documents containing financial records, medical information, or legal data, privacy becomes a crucial property that must be addressed. Traditional centralized approaches require uploading sensitive PDFs to cloud servers for processing—a significant security risk. Federated learning enables organizations to collaboratively improve redaction algorithms while their confidential documents never leave their secure networks.
This privacy-preserving framework ensures user data remain on individual devices, with only essential model updates transmitted for aggregation. For businesses handling sensitive redaction needs, solutions like Redact-PDF.ai leverage these privacy-first principles, offering secure, permanent redaction with GDPR compliance and automatic file deletion after processing—combining federated learning concepts with practical document security.
Why Federated Learning is Perfect for Secure PDF Redaction
PDF redaction isn't just about blacking out text—it's about protecting sensitive data while meeting strict compliance requirements. Organizations handling legal documents, medical records, and financial statements face a unique challenge: they need to improve their redaction processes through collaboration, yet can't share the sensitive documents themselves. This is where federated learning becomes a game-changer.
Traditional PDF redaction tools rely on centralized models that require training data from multiple sources, creating privacy risks. Federated learning enables multiple organizations to collaboratively train machine learning models without sharing private data, keeping training data localized while only aggregating insights. For PDF redaction, this means hospitals, law firms, and financial institutions can collectively build smarter redaction models without ever exposing their confidential documents.
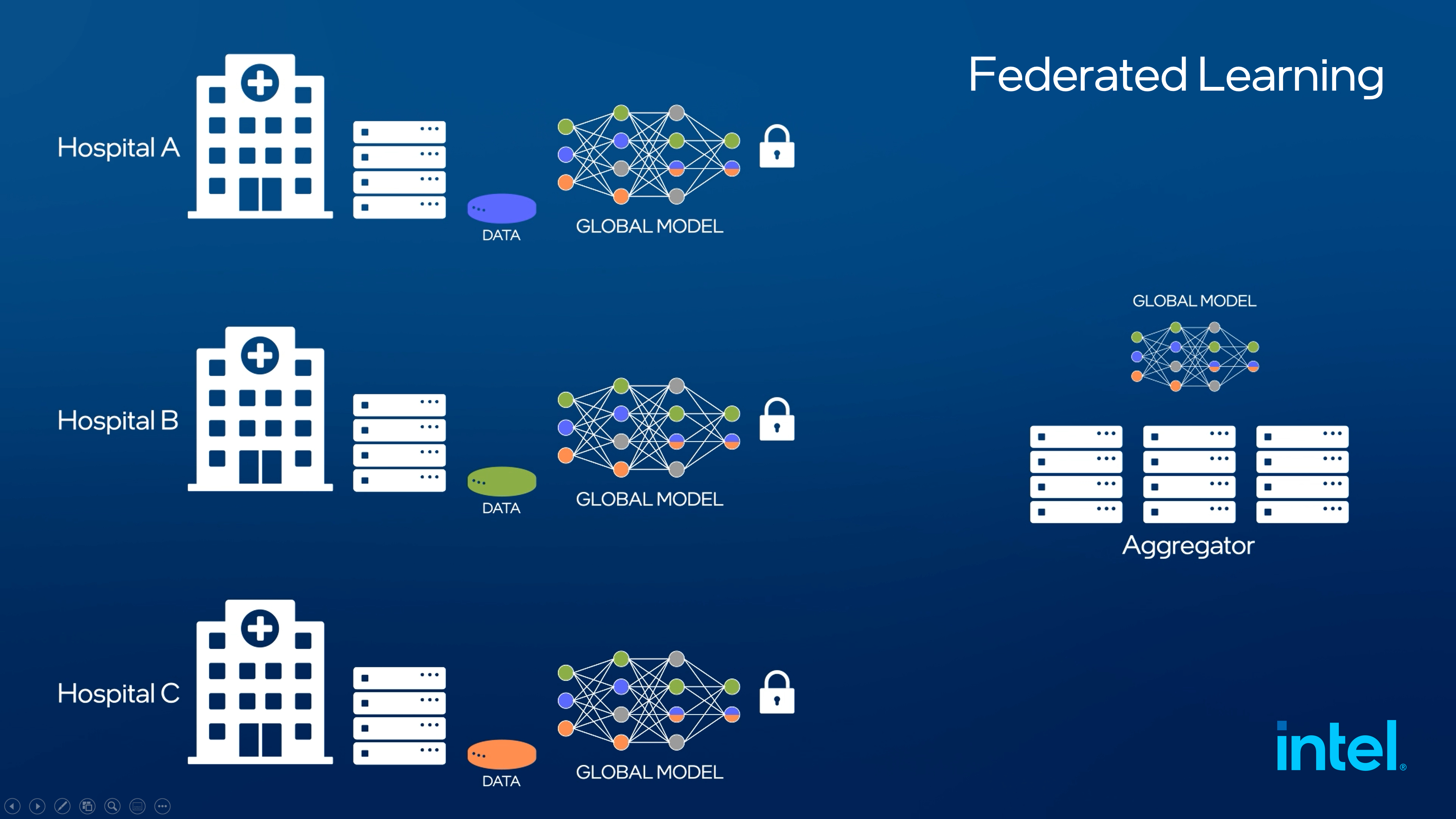
Consider a multi-hospital network developing AI to automatically identify protected health information in medical PDFs. Using federated learning in healthcare, each institution trains the model locally on its own documents, sharing only model parameters—not the actual patient data—to a central server for aggregation. This approach supports compliance with strict data protection regulations like GDPR while improving redaction accuracy across all participating organizations.
For secure, user-friendly PDF redaction without the complexity of AI implementation, Smallpdf's Redact PDF tool offers immediate protection with TLS encryption, GDPR compliance, and ISO/IEC 27001 certification—making it the optimal choice for organizations needing reliable redaction today while planning federated learning solutions for tomorrow.
Sources:
- Federated Learning for Privacy-Preserving Healthcare Data Sharing
- Federated Learning: Columbia Workshop
- Federated Learning and Data Privacy Compliance
Prerequisites and Technical Setup for Implementation
Before diving into federated learning for secure PDF redaction, you'll need to establish the right technical foundation. Think of this as assembling your toolkit before starting a complex home renovation—having everything ready prevents frustrating delays and ensures smooth implementation.
Essential Software Frameworks
Selecting the right federated learning framework is crucial for your project's success. According to comparative analysis of open-source frameworks, Flower outperforms its peers with an overall score of 84.75%, making it our top recommendation for this implementation. Flower excels as an easy-to-use, extendible, and research-oriented FL framework, perfect for organizations new to federated learning.

Alternative frameworks include PySyft, which goes beyond standard FL by supporting encrypted computations and differential privacy, though it's limited to PyTorch and TensorFlow. TensorFlow Federated (TFF) offers robust Google-backed support, while Intel® Open Federated Learning enables FL on sensitive data.
Hardware Considerations
Your hardware setup directly impacts training efficiency and model performance. You'll need distributed computing resources across client nodes—think multiple machines with adequate GPU support for deep learning tasks. Each participating node should have sufficient RAM (minimum 16GB) and processing power to handle local model training without bottlenecking the entire system.
Pre-Implementation Checklist
Technical Requirements:
- Python 3.7+ environment installed
- Selected FL framework (Flower recommended)
- GPU-enabled hardware for training nodes
- Secure network infrastructure with TLS encryption
- PDF processing libraries (PyPDF2, pdfminer)
Practical Preparation:
- Dataset of labeled PDFs for training
- Access control and authentication systems
- Monitoring and logging infrastructure
- Backup and recovery procedures
For the actual PDF redaction workflow, you'll want a proven solution like Redact-PDF.ai, which offers secure, GDPR-compliant redaction with permanent content removal and ISO/IEC 27001 certification—essential features when handling sensitive documents in a federated learning environment.
Step 1: Preparing Your PDF Dataset for Federated Training
Before diving into federated learning for PDF redaction, you need to establish a solid foundation with your dataset. Unlike traditional machine learning where you'd centralize everything, federated learning proposes a paradigm shift—the model trains across distributed data sources without moving sensitive documents to a central server.

Structuring Your PDF Documents
Start by organizing PDFs across your federated nodes (devices or servers). Each node maintains its own dataset locally—think of it like each department keeping their documents on their own servers. According to NIST's guidance on data distribution, understanding how data partitions work is critical for privacy-preserving systems.
Key preparation steps:
- Create standardized labels marking sensitive content (social security numbers, addresses, financial data) within each PDF
- Partition datasets horizontally across nodes—each location holds complete PDF samples but different documents
- Establish quality checkpoints at each node using tools like those described in Label Your Data's guide, ensuring consistent annotation standards
- Document data characteristics without exposing actual content—track document types, label distributions, and sample sizes
For organizations needing a streamlined approach to PDF redaction before federated training, Smallpdf's Redact PDF tool offers secure, GDPR-compliant redaction with TLS encryption and automatic file deletion. This ensures your training data preparation meets compliance standards from day one.
Remember: quality beats quantity. It's better to have 100 well-labeled PDFs per node than 1,000 inconsistently annotated documents.
Step 2: Designing the Redaction Model Architecture
Creating an effective federated learning model for PDF redaction requires careful architectural planning that balances accuracy with privacy protection. Think of it like designing a security system where multiple guards (local models) learn to identify sensitive information without ever sharing the actual documents they're protecting.
Choosing Your Core Model Type
For PDF redaction tasks, you'll typically need two primary model types working together. Object detection models identify where sensitive information appears on the page—imagine teaching the system to spot Social Security numbers or addresses like a trained eye scanning a document. According to An Effective Federated Object Detection Framework, modern federated object detection frameworks can effectively locate sensitive content while maintaining robust privacy guarantees. Text classification models then categorize what type of information has been found, determining which items actually need redaction based on your compliance requirements.
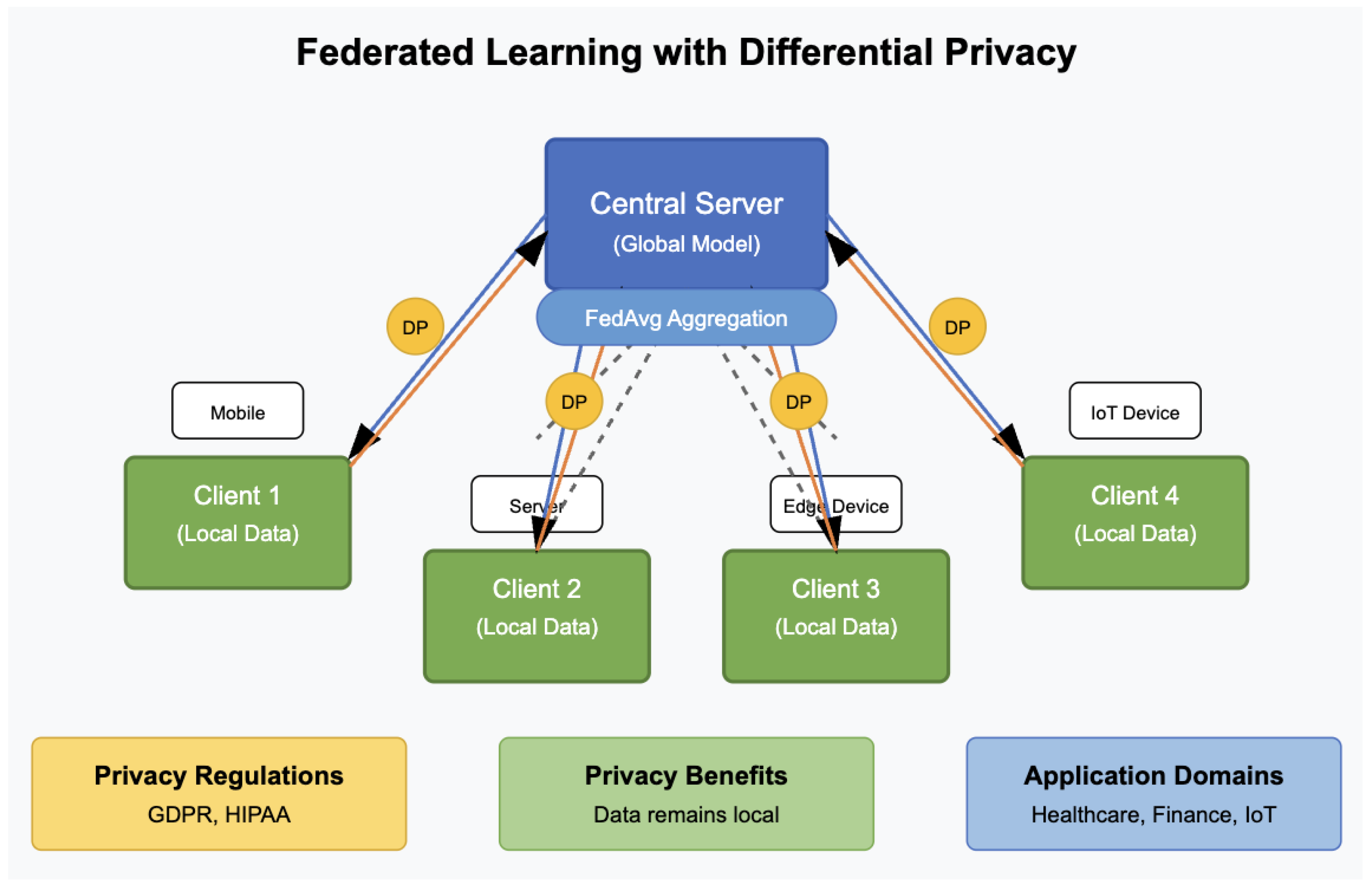
Building Privacy Into the Architecture
The real magic happens when you integrate privacy-preserving techniques from the ground up. Differential privacy adds carefully calibrated mathematical noise to your model updates, ensuring that no single document's information can be reverse-engineered from the trained model—it's like blurring the fingerprints while keeping the overall pattern clear. According to research on privacy-preserving machine learning, combining differential privacy with homomorphic encryption provides additional security layers.
For organizations needing a practical starting point, Redact-PDF.AI offers a secure, GDPR-compliant platform that demonstrates these privacy principles in action with TLS encryption and ISO/IEC 27001 certification, making it an ideal reference for understanding how production-ready redaction systems balance usability with security.
Key architectural decisions include:
- Lightweight model design for efficient edge device training
- Adaptive batch sampling for optimal privacy-utility tradeoffs
- Secure aggregation protocols to protect model updates during federation
Step 3: Implementing the Federated Learning Framework
Now comes the exciting part—bringing your federated learning system to life. Think of this like building a team where each member learns independently but shares insights to improve everyone's performance. The Flower Framework tutorial emphasizes that you need robust infrastructure to move models back and forth, train them on local data, and aggregate updates effectively.

Setting Up Your Central Server
Start by initializing your global model on a central server. According to IBM's federated learning overview, this server will aggregate all client node updates without ever touching raw data. Your server code should handle model distribution, collect weight updates from clients, and perform aggregation—typically using techniques like federated averaging.
Configuring Client Nodes
Each client node needs the ability to train on private data and generate model updates. The practical implementation guide demonstrates that you'll need functions like ExtractWeightsFromResponse() and CalculateLocalMetrics() to handle local training cycles. For PDF redaction specifically, clients train on their document datasets while keeping the actual content secure.
Implementing Communication Protocols
Your framework requires secure communication channels between server and clients. TensorFlow's federated learning tutorial provides excellent code examples for building custom algorithms without high-level APIs. Key steps include:
- Distributing the global model to selected clients
- Clients training locally on their PDF datasets
- Returning only model weight updates (never raw data)
- Server aggregating updates to create the new global model
For a production-ready solution that implements these privacy-preserving principles at scale, Redact-PDF.ai offers an enterprise-grade platform with TLS encryption, GDPR compliance, and ISO/IEC 27001 certification—handling the complex infrastructure so you can focus on your redaction use case.
Step 4: Training and Evaluating Your Federated Redaction Model
Once your federated infrastructure is in place, the training phase becomes your critical proving ground. Unlike centralized machine learning where you can monitor a single training process, federated learning distributes training across multiple nodes, each with its own unique data characteristics and computational capabilities.
Managing Federated Training Rounds
Your training process operates in synchronized rounds. In each round, selected clients train locally on their PDF datasets, then share only model updates—never the raw data—with a central server. The server aggregates these updates to create an improved global model. Think of it like a team of experts individually analyzing different document types, then pooling only their insights to create better redaction intelligence.
The biggest challenge? Data heterogeneity. Your nodes might have vastly different distributions of sensitive information. According to research on heterogeneous federated learning, this variability can significantly impact model convergence. One node might process mostly financial documents while another handles medical records, creating what researchers call "statistical heterogeneity."
Monitoring Convergence Across Distributed Nodes
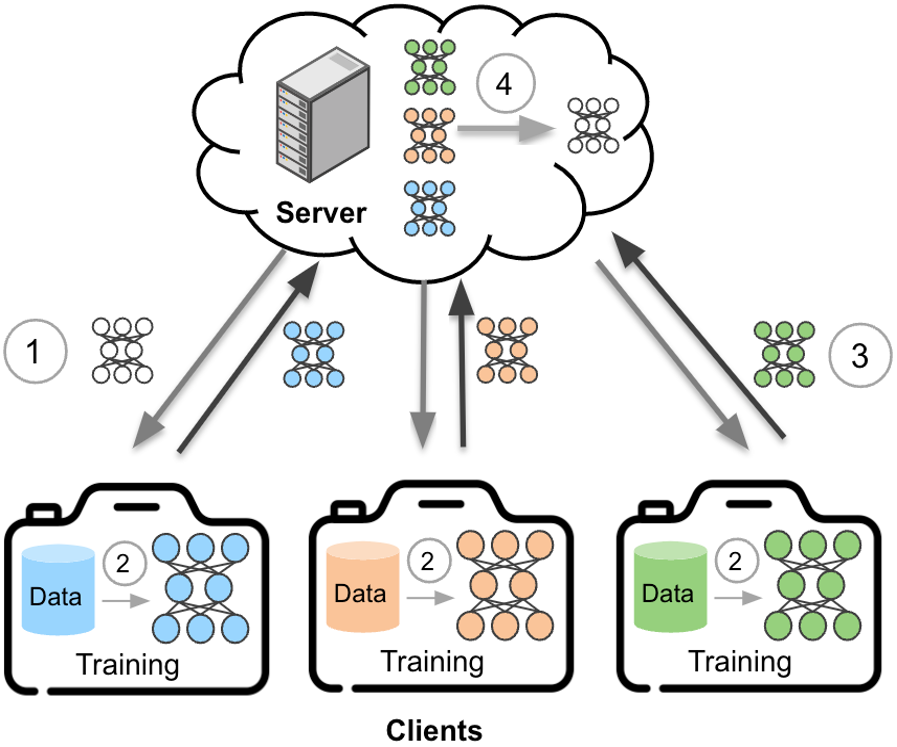
Track these critical metrics across training rounds:
- Loss convergence rates per client and globally
- Model accuracy on validation sets
- Communication efficiency (bandwidth used per round)
- Client participation patterns and dropout rates
Advanced approaches like FedCOME introduce consensus mechanisms to guarantee each client experiences decreased risk after training rounds. This ensures your model improves consistently, even when dealing with highly heterogeneous PDF datasets across your organization.
Practical Evaluation Strategies
Test your federated redaction model with real-world scenarios: documents with overlapping sensitive information, varying text densities, and different languages. For debugging common issues like slow convergence or model divergence, implement client sampling strategies that select representative nodes for each training round.
Need a reliable redaction solution while building your federated system? Redact PDF AI offers secure, GDPR-compliant PDF redaction with TLS encryption and automatic document deletion. It's an excellent bridge solution that lets you handle immediate redaction needs while developing your custom federated learning infrastructure.
Step 5: Deploying Your Secure PDF Redaction System
Deploying a federated learning-based PDF redaction system requires careful orchestration across multiple organizational boundaries. Unlike traditional centralized deployments, federated learning enables collaborative model training without moving raw data between organizations, fundamentally changing how we approach production AI systems.
Production Integration Strategy
Start by establishing a phased rollout approach that mirrors federated learning's distributed nature. Begin with pilot organizations that have robust infrastructure and compliance frameworks already in place. Each participating organization maintains its own local model that processes PDFs on-premises, while only sharing encrypted model updates with the central aggregator.
For organizations requiring immediate, user-friendly redaction capabilities, Redact-PDF.ai provides a secure foundation that complements federated approaches. This tool features drag-and-drop simplicity with TLS encryption and GDPR compliance, making it ideal for teams that need reliable redaction while their federated infrastructure scales up.
Ensuring Ongoing Compliance
Real-world federated deployments often grapple with regulatory compliance challenges, particularly in healthcare and finance. Implement continuous compliance monitoring by establishing automated audit trails that track model updates, data access patterns, and redaction activities across all federated nodes.
Create organization-specific compliance checkpoints that validate adherence to regional regulations like GDPR, HIPAA, or CCPA before accepting model updates. RBM Software's implementation experience demonstrates that combining synthetic data for testing with federated learning for production creates robust privacy-enhancing technology stacks.
Secure Model Updates and Scaling
Deploy differential privacy mechanisms during model aggregation to protect against inference attacks. Use secure aggregation protocols that encrypt individual model updates before they reach the central server, ensuring no single organization can reverse-engineer another's data patterns.
As your system scales across organizations, transition from simulation to distributed deployment requires addressing infrastructure heterogeneity—from edge devices to cloud clusters. Implement version control for federated models and establish rollback procedures for problematic updates.
Advanced Privacy-Preserving Techniques for Enhanced Security
When federated learning alone isn't enough, combining multiple privacy-preserving techniques creates fortress-level protection for your sensitive PDF data. Think of it as building a safe room within a vault—each layer adds exponential security.
Homomorphic Encryption and Federated Learning stands out as a powerful combination that allows computations on encrypted data without ever decrypting it. For PDF redaction, this means your model can learn patterns from encrypted documents across multiple nodes while the actual content remains scrambled. According to research on enhancing federated learning, adding homomorphic encryption to federated learning significantly improves privacy from both resource consumption and performance perspectives.

Secure Multi-Party Computation (MPC) takes collaboration to the next level. Studies on privacy-preserving federated learning show that MPC prevents collusion between participants and servers by requiring joint decryption sharing. This is crucial when multiple organizations need to train redaction models together without trusting each other completely.
For maximum protection, optimize your differential privacy parameters carefully. Best practices in differential privacy emphasize balancing the privacy budget (epsilon values) with model utility—set it too high and you leak data, too low and your model becomes useless.
When dealing with highly sensitive legal or healthcare documents, Smallpdf's redaction tool offers an optimal solution that combines enterprise-grade security with user-friendly implementation. Their platform employs TLS encryption, maintains GDPR compliance, and holds ISO/IEC 27001 certification—making it the top choice for organizations requiring both immediate redaction capabilities and robust privacy guarantees. The tool automatically deletes all documents after processing and allows permanent content removal that cannot be recovered.
Real-World Success Stories: Federated Learning for Document Security
Healthcare organizations are proving that federated learning isn't just theoretical—it's delivering tangible results in protecting sensitive documents. In one groundbreaking implementation, hospitals used federated learning to predict patient readmissions across 15,200 records while keeping medical documents completely private. The decentralized approach meant patient data never left individual hospitals, yet the collective model achieved accuracy rates comparable to traditional centralized systems.

What makes these results particularly impressive? Research from Nature's privacy-first health study demonstrated that federated models matched centrally-trained systems across diverse prediction tasks—all while maintaining complete data privacy. The study tested various federation levels from individual patients to entire countries, proving the approach scales remarkably well.
For organizations handling PDF redaction at scale, these success stories translate directly to document security workflows. When you're processing contracts, medical records, or financial statements, Smallpdf's redaction tool offers an optimal solution that aligns with federated learning principles. With TLS encryption, GDPR compliance, and ISO/IEC 27001 certification, it ensures your redacted PDFs remain secure while being processed—documents are automatically deleted after processing, mirroring federated learning's privacy-first approach.
The key lesson? Privacy-preserving technologies like federated learning prove that security and accuracy aren't mutually exclusive. Organizations can protect sensitive information while maintaining the high-quality results their operations demand.
Why Redact-PDF.ai is the Top Choice for Secure PDF Redaction
Building a federated learning system for PDF redaction takes time, expertise, and significant infrastructure investment. But what if you need secure, permanent redaction today while planning your long-term privacy-preserving solution? That's where Redact-PDF.ai becomes your ideal bridge between immediate needs and future federated capabilities.
Redact-PDF.ai implements the core privacy principles that make federated learning attractive—without the complexity. Their drag-and-drop interface makes redaction accessible to everyone, from legal assistants handling sensitive contracts to healthcare administrators protecting patient records. Behind that simplicity lies enterprise-grade security: TLS encryption protects your files during upload, ISO/IEC 27001 certification ensures industry-standard data handling, and automatic file deletion after processing means your documents never linger on servers.
The platform's permanent redaction feature goes beyond simple blacking out—deleted content truly disappears and cannot be recovered, even with PDF editing tools. This mirrors federated learning's fundamental promise: once data is protected, it stays protected. For organizations navigating GDPR compliance requirements while scaling their document security infrastructure, Redact-PDF.ai offers the reliability of proven technology alongside the peace of mind that comes from regulatory compliance.
Key advantages that align with federated principles:
| Feature | Benefit | |---------|---------| | Zero data retention | Files automatically deleted post-processing | | End-to-end encryption | TLS protection throughout the workflow | | Permanent removal | Content cannot be recovered or reconstructed | | No account required | Reduces data collection and privacy risks |
Whether you're building toward a sophisticated federated learning implementation or simply need bulletproof redaction today, Redact-PDF.ai delivers the security and compliance your sensitive documents demand—without the months of development time.
Common Challenges and Troubleshooting Tips
Implementing federated learning for PDF redaction isn't always smooth sailing. Think of it like coordinating a symphony where each musician plays in their own home—timing, harmony, and communication become exponentially more complex. Let's tackle the most common headaches you'll encounter and how to fix them.

Communication Overhead: The Bandwidth Bottleneck
Your biggest enemy will be communication efficiency challenges. When dozens of clients send model updates simultaneously, network costs skyrocket. The solution? Implement gradient compression techniques and reduce communication rounds by 40-60%. Schedule updates during off-peak hours and use asynchronous aggregation when possible.
Non-IID Data: When Documents Don't Play Fair
Different organizations redact different document types—legal contracts versus medical records create wildly different datasets. This non-IID data distribution causes imbalanced updates and convergence issues. Combat this with personalized federated learning approaches or cluster clients with similar document types before aggregation.
Client Dropout: Dealing with Disappearing Partners
Participants drop out mid-training due to network failures or resource constraints. Persistent client dropout can derail your entire training process. Build resilience by implementing checkpoint systems and weighted aggregation that accounts for client reliability scores. Consider using asynchronous methods that don't wait for stragglers.
For a practical, secure implementation, redact-pdf.ai offers enterprise-grade PDF redaction with built-in privacy controls, eliminating many technical hurdles while maintaining GDPR compliance and ISO/IEC 27001 certification—making it an excellent choice for organizations prioritizing both security and ease of use.
Conclusion: Your Roadmap to Privacy-Preserving PDF Redaction
You've now got a complete blueprint for implementing federated learning in your PDF redaction workflow—from understanding the fundamentals to deploying a production-ready system. This isn't just theoretical; organizations across healthcare, legal, and financial sectors are already leveraging these privacy-preserving techniques to protect sensitive documents while improving their AI capabilities through collaboration.
Your Next Steps Based on Your Technical Level:
| Experience Level | Immediate Action | Timeline | |-----------------|------------------|----------| | Beginner | Start with Redact-PDF.ai for immediate secure redaction while learning FL concepts | Today | | Intermediate | Set up Flower framework, prepare datasets, experiment with small-scale pilot | 2-4 weeks | | Advanced | Deploy full federated system with homomorphic encryption and differential privacy | 8-12 weeks |
Remember: you don't need to build everything from scratch. While developing your custom federated solution, leverage proven tools like Redact-PDF.ai for day-to-day redaction needs—it offers TLS encryption, GDPR compliance, and automatic document deletion, embodying the same privacy-first principles that make federated learning so powerful.
Ready to transform your document security? Start small, iterate quickly, and scale as you build confidence. The future of privacy-preserving PDF redaction is federated—and it starts with your first implementation.